WebRTC and Audio Watermarking in Real-Time Systems
Introduction
In a world where real-time communication is becoming the default (voice calls, live streams, online meetings), it is increasingly difficult to know who (or what) is on the other side of the connection. Advances in AI have made it possible to generate highly realistic synthetic voices that can mimic identity, tone, and intent with alarming accuracy. Unlike manipulated images or videos, which people have at least begun to question, fake audio remains much harder for humans to detect. You may be listening to a voice that sounds familiar, trustworthy, even authoritative, without any reliable way to verify its authenticity.
This is particularly concerning in live scenarios. In a pre-recorded setting, content can be analyzed, scanned, or verified after the fact. But in real-time communication, there is no such luxury. Decisions are made instantly, conversations unfold dynamically, and trust is assumed by default. This creates a perfect environment for misuse, from impersonation and fraud to misinformation and social engineering.
One promising approach to this problem is audio watermarking, embedding imperceptible signals into audio that can later be used to verify its origin or integrity. However, while watermarking works well in controlled, offline environments, deploying it in real-time systems is significantly more complex. In practice, audio does not travel cleanly from speaker to listener. It is continuously transformed, compressed, filtered, and adapted to network conditions. Each of these steps can distort or destroy the embedded watermark.
This is where technologies like WebRTC come into play. As the backbone of most modern real-time communication systems, WebRTC defines how audio is captured, processed, transmitted, and reconstructed across networks. Understanding this pipeline is essential if we want to design watermarking systems that can survive in real-world conditions, not just in theory, but in the messy, unpredictable environment of live communication.
What Is WebRTC?
WebRTC (Web Real-Time Communication) is an open-source framework and set of browser APIs that enables peer-to-peer audio, video, and data communication directly between browsers and devices, without requiring a plugin or intermediate server to relay media. Originally developed by Google and standardized by the W3C and IETF, WebRTC has become the backbone of modern real-time communication on the web.
What makes WebRTC particularly interesting and challenging from an audio engineering perspective is what happens to the audio signal before it ever leaves the sender's device, and after it arrives at the receiver's. The audio is not simply recorded and streamed. It passes through an elaborate pipeline of signal processing, compression, packetization, network transmission, and reconstruction, each stage designed to maximize quality and minimize latency under unpredictable network conditions. For audio watermarking, every one of these stages is a potential threat.
The diagram below illustrates the full WebRTC audio pipeline, from microphone to speaker:
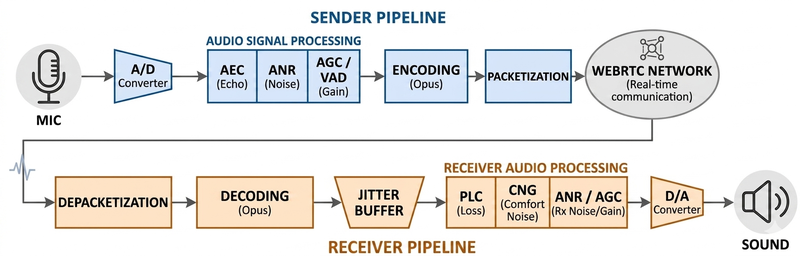
Let us walk through each stage in detail.
The Sender Pipeline
Stage 1 — Audio Capture and A/D Conversion
The pipeline begins at the microphone. The analog acoustic signal captured by the mic is converted into a digital signal by an Analog-to-Digital (A/D) converter. This process involves sampling the continuous waveform at a discrete rate (typically 48 kHz in WebRTC) and quantizing the amplitude values to a fixed bit depth (usually 16 or 32 bits).
Why it exists in WebRTC: Digital processing is a prerequisite for everything that follows. Without digitization, no downstream processing (filtering, encoding, transmission) is possible.
Effect on the audio signal: The A/D conversion is generally transparent if performed at adequate sample rates and bit depths. Quantization noise is negligible at 16 bits and above.
Impact on watermarking: This stage is largely benign for watermarking. If the watermark is embedded in the digital domain before capture (e.g., injected into the audio stream in software), the A/D stage is already behind the watermarking point. However, if audio is captured from a loudspeaker via a microphone (the "over-the-air" scenario), the re-digitization process introduces acoustic channel noise, room reflections, and frequency response distortions that can significantly degrade a watermark not designed for such conditions.
Stage 2 — Audio Signal Processing (AEC, ANR, AGC/VAD)
Before encoding, WebRTC applies a suite of real-time signal processing algorithms collectively known as Audio Processing Modules (APM). These operate on short frames of audio (typically 10–20 ms) and are responsible for three distinct functions:
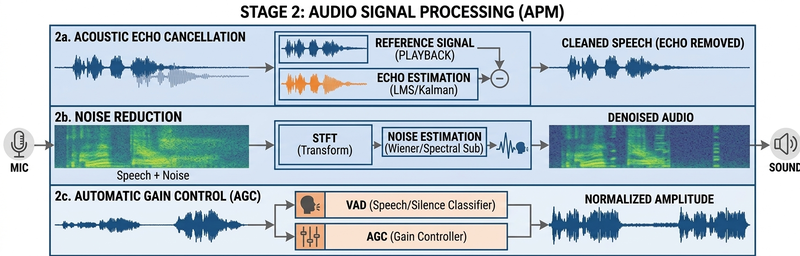
2a. Acoustic Echo Cancellation (AEC)
AEC detects and removes the echo caused by audio from the loudspeaker leaking back into the microphone. It works by maintaining a reference signal of what is being played out and adaptively subtracting the estimated echo from the microphone input using techniques like Least Mean Squares (LMS) or more sophisticated Kalman-based filters.
Why it exists: Without AEC, participants on the far end would hear their own voice echoed back with a delay, making conversation difficult to follow.
Effect on the audio signal: AEC applies adaptive filtering that continuously estimates and subtracts a component of the signal. This is a non-linear, time-varying operation. In double-talk conditions (when both parties speak simultaneously), AEC must suppress its adaptation to avoid distorting the near-end speaker's voice, which can leave residual echo.
Impact on watermarking: AEC is particularly dangerous for embedded watermarks. The adaptive filter treats any consistent low-energy pattern in the microphone signal that correlates with the loudspeaker output as potential echo, including a watermark that happens to share spectral or temporal characteristics with the playback signal. The subtraction operation directly modifies the waveform, and even a well-designed watermark embedded in the time domain can be partially or fully erased. Watermarking strategies must account for this by embedding signals that are statistically orthogonal to typical loudspeaker playback.
2b. Automatic Noise Reduction (ANR)
ANR (also called Noise Suppression, NS) estimates the background noise profile (keyboard clicks, fan hum, street noise) and attenuates it from the captured signal. WebRTC uses spectral subtraction or Wiener filter-based approaches, operating in the frequency domain on short-time Fourier transform (STFT) frames.
Why it exists: Background noise degrades speech intelligibility and is annoying for the remote participant. ANR improves perceived audio quality, especially in non-ideal environments.
Effect on the audio signal: ANR applies frequency-dependent gain reduction. Frequency bands classified as "noise-dominated" are attenuated, sometimes aggressively. This introduces spectral shaping of the signal and, in cases of over-suppression, can introduce "musical noise", a characteristic artifact of spectral subtraction.
Impact on watermarking: ANR is one of the most destructive stages for audio watermarks. If the watermark signal has a flat or pseudo-noise spectral profile, the noise suppressor will classify it as background noise and attenuate it. Watermarks embedded in mid-to-high frequency bands with low perceptual salience are especially vulnerable. Robust watermarking in WebRTC environments must either embed information in frequency regions that ANR protects (i.e., regions with strong speech energy), or adapt the embedding to the noise estimator's behavior.
2c. Automatic Gain Control (AGC) and Voice Activity Detection (VAD)
AGC normalizes the signal level by dynamically adjusting gain to maintain a consistent output amplitude regardless of how close or far the speaker is from the microphone, or how loud they speak. VAD detects whether a given frame contains active speech or silence, and can trigger comfort noise generation or bitrate reduction during silent periods.
Why it exists: AGC ensures that quiet speakers are not inaudible and loud speakers do not clip. VAD enables bandwidth savings during silence and is a prerequisite for AGC adaptation.
Effect on the audio signal: AGC applies time-varying gain, which changes the amplitude envelope of the signal. VAD classifies frames as speech or non-speech, and non-speech frames may be handled differently by the encoder.
Impact on watermarking: AGC directly scales the signal amplitude, which affects any amplitude-based watermarking scheme. If the watermark is embedded at a fixed amplitude relative to the original signal, AGC will alter the signal-to-watermark ratio. Time-domain watermarks that rely on precise amplitude relationships are particularly vulnerable. Additionally, VAD-triggered silence suppression may drop or alter frames that carry watermark information, creating gaps in the embedded signal.
Stage 3 — Encoding (Opus)
After preprocessing, the audio signal is compressed using the Opus codec, the default and recommended codec for WebRTC audio. Opus is a highly versatile, open-source codec that can operate at bitrates from 6 kbps to 510 kbps. It supports only five discrete internal sampling rates: 8 kHz (narrowband), 12 kHz (medium-band), 16 kHz (wideband), 24 kHz (super-wideband), and 48 kHz (fullband), which means non-native input rates (e.g. 44.1 kHz) are silently resampled before encoding, introducing an additional layer of signal modification. Internally, Opus switches between SILK (a speech coding algorithm optimized for voice) and CELT (a low-latency transform codec based on the Modified Discrete Cosine Transform) depending on content and bitrate.
Why it exists: Raw PCM audio at 48 kHz / 16-bit stereo consumes approximately 1.5 Mbps. For real-time communication over typical internet connections, compression is essential. Opus achieves excellent speech quality at 20–40 kbps while maintaining very low algorithmic latency (~5–26.5 ms depending on frame size).
Effect on the audio signal: Opus is a lossy codec. It exploits perceptual masking to discard audio information that the human auditory system is deemed unlikely to notice. In CELT mode, the spectrum is divided into bands along a Bark-like scale, and each band is allocated bits according to its perceptual importance and the available budget. The quantization of MDCT coefficients and the use of predictive coding introduce distortion that is perceptually shaped but spectrally non-trivial. At lower bitrates, the codec aggressively quantizes mid and high frequencies.
Critically, when the bit budget for a high-frequency band drops to zero, Opus does not simply leave silence. Instead, it activates a mechanism called band folding (spectral folding): spectral coefficients from a lower band are copied into the under-funded band, their signs are pseudo-randomly flipped, and the result is scaled to an estimated energy level. This synthesizes spectral content that was not present in the original signal. The effect is perceptually preferable to a hard spectral cutoff, which would sound muffled, but it means the codec is actively injecting new energy into frequency regions where the original had none.
Empirical analysis at 24 kHz. To visualize these effects, we passed a speech signal through Opus at three bitrates using a 24 kHz sampling rate (Nyquist limit: 12 kHz). The figures below compare the original spectrogram, the Opus-encoded spectrogram, and their difference (positive/red = original louder, negative/blue = Opus louder, white = no difference):
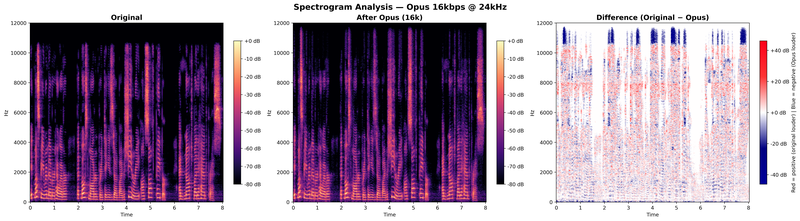
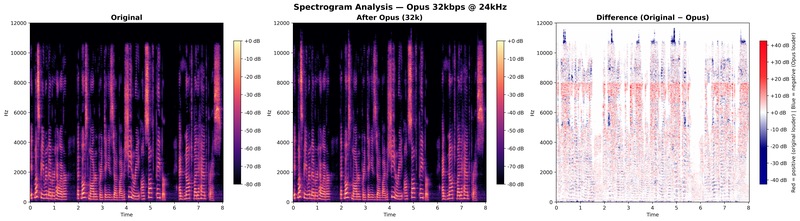
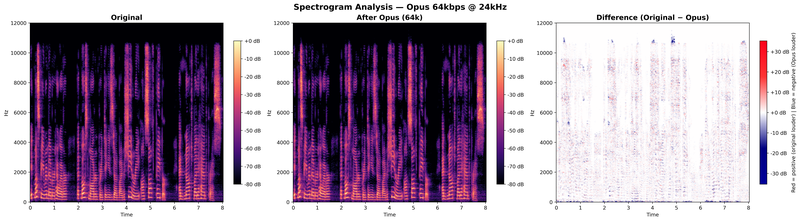
The per-band statistics quantify the degradation:
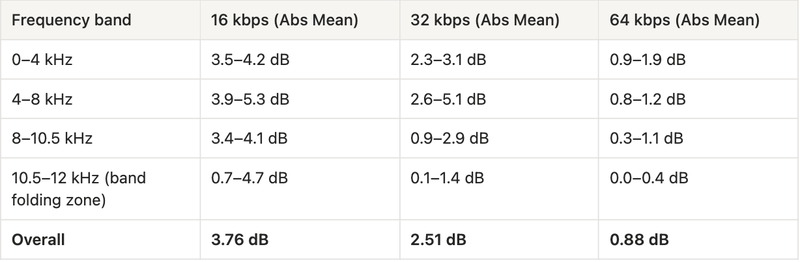
At 16 kbps, the band folding zone (10.5–11.5 kHz) shows negative mean differences of –4.35 to –4.71 dB, meaning Opus is louder than the original, injecting energy where there was none. At 64 kbps, this effect is negligible and the overall distortion drops below 1 dB.
The 16 kHz case (what our benchmark actually tests). The analysis above uses 24 kHz to reveal the full picture, including band folding. But in a typical WebRTC voice pipeline, audio is often downsampled to 16 kHz before encoding. At this rate, the Nyquist limit is 8 kHz, the entire signal lives within a single octave of speech-critical frequencies, and there are no high-frequency bands left for band folding to operate on.
This changes the character of the degradation. At 16 kHz, Opus engages its SILK mode (optimized for speech) rather than CELT, and all available bits are concentrated on the 0–8 kHz range. The spectrogram comparison at 16 kHz / 16 kbps shows the effect:
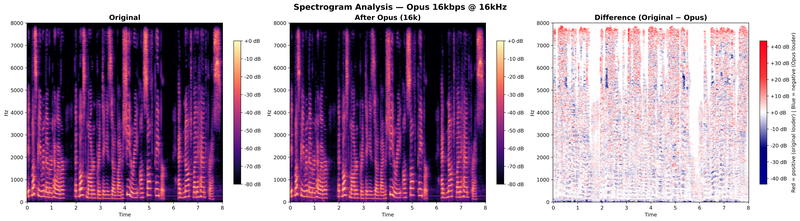
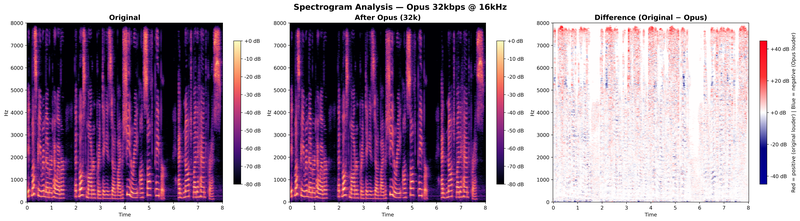
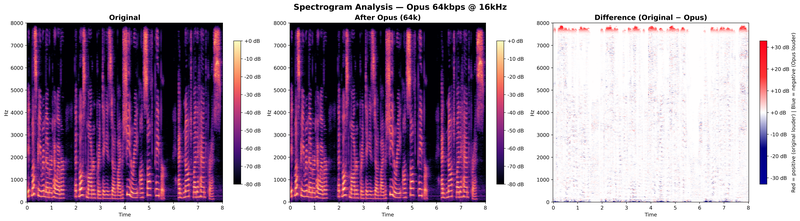
Two things stand out. First, the overall distortion is slightly lower at 16 kHz than at 24 kHz for the same bitrate, because the same 16 kbps budget is spread over half the bandwidth. Second, there is no band folding contamination: everything above 8 kHz is simply absent. The damage is purely quantization-based, concentrated in the speech band itself.
This is precisely the scenario our benchmark evaluates, and arguably the most challenging one for watermarking. The watermark has nowhere to hide: the entire available spectrum (0–8 kHz) is subject to aggressive quantization, with the 7.5–8 kHz edge suffering nearly 4 dB of distortion even before network effects are applied. There are no "safe" high-frequency bands that escape the codec's attention, because the codec's attention is all there is.
Impact on watermarking: Lossy compression is one of the most well-studied threats to audio watermarking, and Opus is no exception. The codec's perceptual model does not consider the watermark signal as "important" information (it is, by design, inaudible) and therefore it is highly susceptible to being removed or severely degraded during compression.
The threat operates through two distinct mechanisms, whose relative importance depends on sampling rate:
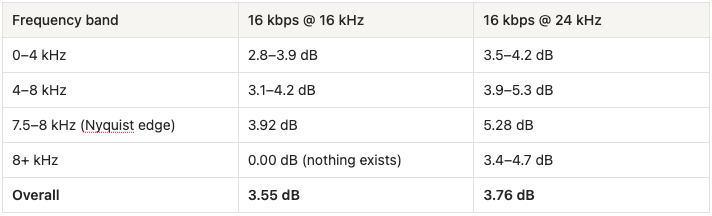
- Quantization loss (dominant at all sampling rates). Transform-domain quantization directly attacks frequency-domain watermarks by discarding fine spectral detail. At 16 kHz / 16 kbps (the configuration our benchmark uses) even the perceptually significant low-frequency bands (0–4 kHz) suffer 2.8–3.9 dB of average distortion. This is the primary and unavoidable threat: the watermark must survive inside the same narrow band that the codec is aggressively compressing.
- Band folding contamination (significant at higher sampling rates). At 24 kHz and above, frequency regions where the codec has insufficient bits are not left silent; band folding replaces the original spectral content, including any embedded watermark, with synthesized energy derived from lower bands. This is not merely attenuation; the original information is overwritten with unrelated spectral content. At 16 kHz this mechanism is absent (there are no bands above Nyquist to fold into), but it becomes a serious additional threat if the pipeline operates at higher sampling rates.
Spread-spectrum and echo-hiding watermarks may survive at higher bitrates (64+ kbps, where overall distortion stays below 1 dB), but at typical WebRTC bitrates the codec creates a hostile environment for any embedded signal. The most effective mitigation strategy is to concentrate the watermark in the lowest frequency bands (0–4 kHz), those to which the codec allocates the most bits and which remain most faithfully preserved even at the lowest bitrates. At 16 kHz / 16 kbps, this is not merely the best strategy, it is the only strategy, since the entire usable spectrum is under 8 kHz.
Stage 4 — Packetization
Once encoded, the audio stream is divided into packets for transmission over the network. In WebRTC, audio packets are encapsulated using the Real-time Transport Protocol (RTP), which is transmitted over UDP. Each RTP packet includes a header carrying a sequence number, timestamp, synchronization source (SSRC) identifier, and payload type, followed by the encoded audio payload.
Typical RTP packet sizes correspond to 20 ms of audio at the standard Opus frame size, though this can be tuned. Each packet contains one or more complete Opus frames.
Why it exists: Network transmission requires the data to be broken into discrete units. RTP provides the structure necessary for the receiver to reassemble, sequence, and time-stamp audio frames correctly. UDP is preferred over TCP because it avoids the retransmission delays of TCP, which are unacceptable for real-time audio.
Effect on the audio signal: Packetization itself does not modify the audio waveform. However, the choice of packet size introduces a fundamental latency floor. Smaller packets mean lower latency but higher per-packet overhead, while larger packets are more efficient but increase end-to-end delay.
Impact on watermarking: Packetization creates discrete boundaries in the audio stream. If the watermark is embedded as a continuous signal in the time domain, these boundaries are transparent and pose no direct threat. However, packet loss (discussed below) means that entire segments of the watermarked audio can be lost, creating gaps in the embedded signal. Watermarking algorithms that embed data redundantly across multiple frames, rather than concentrating information in a single frame, are more resilient to this scenario.
Stage 5 — Network Transmission over WebRTC
The packetized audio is transmitted through the WebRTC network layer. WebRTC includes DTLS (Datagram Transport Layer Security) for encryption and SRTP (Secure Real-time Transport Protocol) for protecting audio/video streams from eavesdropping and tampering. ICE (Interactive Connectivity Establishment), STUN, and TURN protocols handle NAT traversal and route selection.
Why it exists: The internet is an unreliable, unordered, variable-latency medium. WebRTC's network stack manages all of the complexity of establishing a direct peer-to-peer connection, handling firewall traversal, encrypting the media, and monitoring network quality in real time.
Effect on the audio signal: The network introduces packet loss, reordering, and variable delay (jitter). Packet loss rates of 1–5% are common on typical internet connections, and spikes can reach 10–20% on poor connections. These losses directly correspond to missing audio frames.
Impact on watermarking: Network transmission is a critical threat vector for watermarking. Packet loss means that portions of the audio, including their embedded watermark, simply never arrive at the receiver. If the watermark is not redundantly encoded, a single lost packet can break the detection chain. Furthermore, SRTP encrypts the payload, which means that on-path inspection or manipulation of the audio stream (e.g., to read or inject a watermark at the network layer) is not feasible, so watermarking must happen at the application layer, before encryption on the sender side and after decryption on the receiver side.
The Receiver Pipeline
Stage 6 — Depacketization
Upon arrival, RTP packets are stripped of their headers, and the encoded audio payloads are extracted. The receiver uses sequence numbers and timestamps to detect out-of-order packets and reorder them into the correct sequence before passing them to the jitter buffer.
Why it exists: Network routing can cause packets to arrive out of order. Depacketization restores logical ordering and provides the jitter buffer with the timing information it needs.
Impact on watermarking: Out-of-order packets that are resequenced correctly pose no threat to the watermark. However, packets that arrive too late to be useful are discarded, which is functionally equivalent to packet loss from the watermark's perspective.
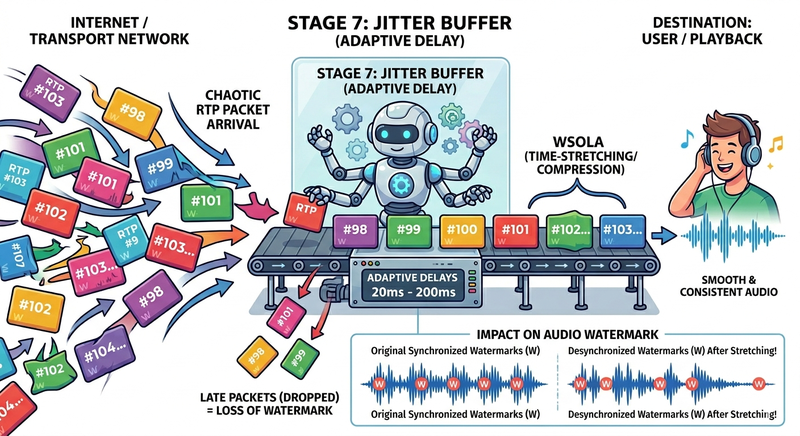
Stage 7 — Jitter Buffer
The jitter buffer is one of the most sophisticated components of the receiver pipeline. It absorbs network jitter, the variation in packet arrival times, by introducing a controlled, adaptive delay. Packets arriving early are held until their scheduled playout time; packets arriving late beyond the buffer's delay window are dropped.
WebRTC uses an adaptive jitter buffer that dynamically adjusts its depth based on observed network conditions. Under stable conditions, the buffer depth may be as low as 20–40 ms; under high-jitter conditions, it may grow to 200 ms or more.
Why it exists: Without a jitter buffer, variable packet arrival times would cause the audio to stutter, speed up, and slow down (making it unintelligible). The jitter buffer converts a bursty, variable-delay network stream into a smooth, consistent audio stream for playback.
Effect on the audio signal: The jitter buffer introduces latency. It may also perform time-stretching or time-compression (using techniques like WSOLA—Waveform Similarity Overlap-Add) to smoothly accommodate clock drift between sender and receiver or to elastically adjust buffer depth without introducing audible discontinuities.
Impact on watermarking: The jitter buffer is a significant challenge for watermarking systems. Time-stretching operations change the temporal position of every sample in the audio signal. Watermarks that rely on precise sample-level timing, such as echo-hiding or fine-grained phase watermarks, can be catastrophically desynchronized by even a small amount of time-scaling. Furthermore, if the jitter buffer's WSOLA operation discards or repeats small segments of audio to adjust the playout rate, it can destroy the coherence of embedded bit sequences. Robust watermarks must be designed to tolerate temporal distortion and must use synchronization markers that allow the detector to re-align with the signal after time-stretching.
Stage 8 — Decoding (Opus)
After the jitter buffer, each audio frame is decoded from its compressed Opus representation back to PCM. The decoder reconstructs the waveform from the transmitted coefficients, using the codec's synthesis model.
Why it exists: The encoded data must be converted back to a form that can drive a digital-to-analog converter for playback.
Effect on the audio signal: Decoding applies the inverse of the encoding process. The decoded PCM will contain the quantization and perceptual coding artifacts introduced during encoding. The decoded signal is not identical to the pre-encoded signal, it is a perceptually similar but numerically different approximation.
Impact on watermarking: Any watermark damage introduced during encoding is permanent at this stage. The decoder cannot recover information that was discarded by the perceptual model. This reinforces the importance of encoding-resilient watermarking strategies.
Stage 9 — Receiver Audio Processing (PLC, CNG, ANR/AGC)
After decoding, the receiver applies another round of audio processing before playback. This includes:
9a. Packet Loss Concealment (PLC)
When a packet is lost or arrives too late, PLC generates a synthetic replacement frame. Simple PLC repeats the last received frame; more sophisticated implementations extrapolate the waveform using pitch and spectral estimation.
Impact on watermarking: PLC-generated frames contain no real watermark. They are synthesized audio, not transmitted audio. As a result, a watermark detector operating on the playout stream will inevitably process a mixture of genuine watermarked frames and synthetic replacements. This can introduce errors, since some segments contain no embedded signal at all.
9b. Comfort Noise Generation (CNG)
During silence periods detected by the sender's VAD, the sender may transmit SID (Silence Insertion Descriptor) packets instead of encoded audio. The receiver uses these to generate artificial background noise that matches the sender's environment, maintaining the psychological sense of an open connection.
Impact on watermarking: CNG-generated audio contains no watermark. Any portion of the session during which CNG is active represents a gap in the embedded watermark signal. For long-form session watermarking, where the payload is spread over the entire session, these gaps are manageable if the redundancy is sufficient. For short, precise watermark payloads, CNG events can cause missed detections.
9c. Receiver-Side ANR and AGC
Similar to the sender-side processing, the receiver may also apply noise reduction and automatic gain control to improve the playout quality for the listener. These operations perform the same amplitude scaling and spectral shaping described earlier.
Impact on watermarking: Any watermark that survived encoding, transmission, and decoding must now survive a second round of ANR and AGC. Double-pass processing compounds the degradation. Watermarks already weakened by sender-side processing may not survive this final stage. This is a strong argument for embedding watermarks at a higher perceptual amplitude than would be necessary for ideal conditions, accepting slightly higher perceptibility in exchange for robustness.
Stage 10 — D/A Conversion and Playback
Finally, the processed PCM signal is converted back to an analog waveform by the Digital-to-Analog (D/A) converter and played through the speaker or headphones.
Impact on watermarking: This stage is transparent to watermark detection if the detection is performed in the digital domain (i.e., on the PCM stream before D/A conversion). If detection must happen in the acoustic domain (for example, via a microphone recording of the loudspeaker output), then all of the challenges of the over-the-air channel (room acoustics, frequency response, clipping) apply.
Summary: The Gauntlet an Audio Watermark Must Survive
To put the full pipeline in perspective, here is a summary of every threat a watermark faces as it travels from sender to receiver:
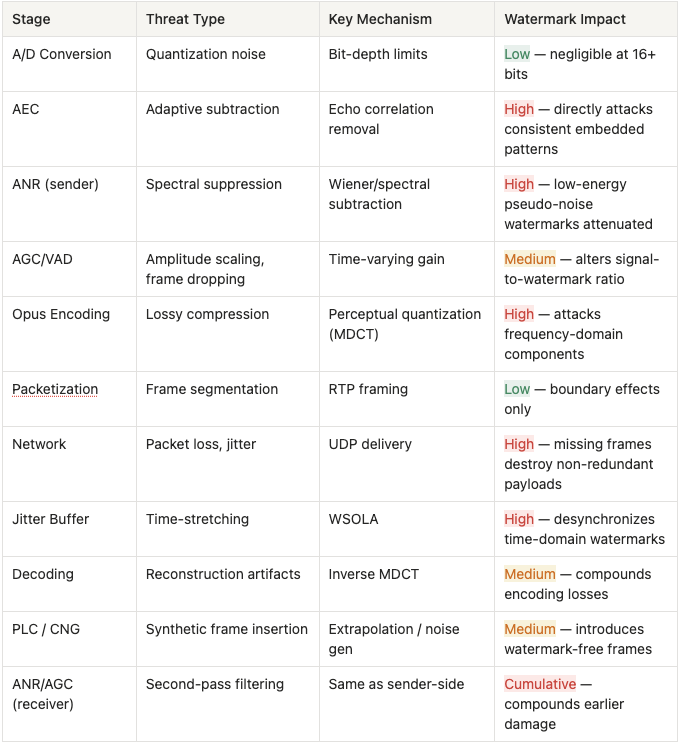
Key Challenges of Watermarking in Real-Time Systems
Having traced the full pipeline, we can now articulate the fundamental challenges that make audio watermarking in WebRTC environments so difficult:
- Cumulative Signal Degradation
The watermark must survive not one or two transformations, but a cascade of more than ten distinct operations, each of which modifies the signal in ways that are not designed with watermark preservation in mind. Damage compounds at each stage. - Latency Constraints
Watermarking in real time means the embedding must happen within a single audio frame (typically 10–20 ms). There is no opportunity to look ahead in the signal or to use long-window analysis techniques that are available in offline processing. The embedder must operate causally and at very low computational cost to avoid adding perceptible latency. - Temporal Desynchronization
The jitter buffer's time-stretching and the variable packet arrival patterns mean that the temporal structure of the signal at the receiver does not perfectly match the structure at the sender. Any watermark detection scheme that relies on sample-accurate alignment must include synchronization mechanisms that can tolerate temporal offsets. - Non-Stationarity of the Processing Chain
AEC adaptation, ANR noise estimation, and AGC gain scheduling all change over time in response to the acoustic environment. The watermark experiences different levels of degradation from frame to frame, making it difficult to design a single set of embedding parameters that provides consistent robustness. - No Control Over the Processing Chain
In most deployment scenarios, the watermarking system sits outside the codec and WebRTC stack. It cannot disable AEC or ANR, nor can it negotiate with the codec to protect specific frequency bins. The watermark must be designed to survive processing that it has no influence over. - Packet Loss Creates Structural Gaps
Unlike offline attacks (e.g., MP3 compression of a file), packet loss in WebRTC is random and unpredictable. A watermark payload spread across 60 seconds of audio might lose 3–5% of its frames on an average call, and 15–20% on a congested connection. The decoding algorithm must be designed to reconstruct the full payload from a partial, gappy observation.
Conclusion
WebRTC represents one of the most challenging environments for audio watermarking, not because any single stage of the pipeline is uniquely destructive, but because the watermark must survive a long, cascaded sequence of adaptive, lossy, and time-varying transformations, all under strict latency and computational constraints. Each stage, from the adaptive echo canceller to the jitter buffer's time-stretcher to the Opus codec's perceptual quantizer, introduces a different class of signal distortion, and a robust watermarking system must be hardened against all of them simultaneously.
The gap between "works in the lab" and "works on a real call" is large. Closing that gap requires moving beyond standard compression benchmarks and embracing the full complexity of real-time audio pipelines. It requires embedding strategies informed by signal processing, codec internals, and network engineering in equal measure.
This is precisely the problem space that DeepMark is working in, and it is exactly the kind of challenge where rigorously engineered solutions make the difference between a watermark that disappears into the noise of the network and one that reliably survives the journey from speaker to listener, carrying its proof of authenticity intact. If you're interested in being among the first to test whether DeepMark watermarks can truly survive the full WebRTC pipeline, we’d be glad to hear from you.




Your Content Deserves the Best Protection
Discover how our innovative AI watermarking tool can transform your digital protection strategy. Request a demo and let us guide you through features tailored to your needs.