The Digital Ear: How Audio Fingerprinting Tracks the World’s Sound

Every second, thousands of hours of audio are broadcast, streamed, and uploaded across radio, television, and podcast platforms. Hidden beneath this constant flow is a fundamental question: how can we reliably identify what is being played in real time, at scale, and under noisy, imperfect conditions? The answer lies in audio fingerprinting technology that turns sound into a compact digital signature, enabling systems to recognize audio even when it has been compressed, distorted, or partially altered.
What Is Audio Fingerprinting?
An audio fingerprint is a compact, robust digital summary of a short audio segment (usually 3–10 seconds). Unlike a full recording, it is designed to remain consistent even when the audio is altered by noise, equalization, speed changes, or low-bitrate compression.
Classic Peak-Based Fingerprinting Process:
- Spectrogram Generation: The audio waveform is transformed into a 2D image using Short-Time Fourier Transform (STFT) or Constant-Q Transform.
- Peak Detection: The system identifies local energy maxima (“peaks”), the most prominent frequency-time points that stand out even in noisy environments.
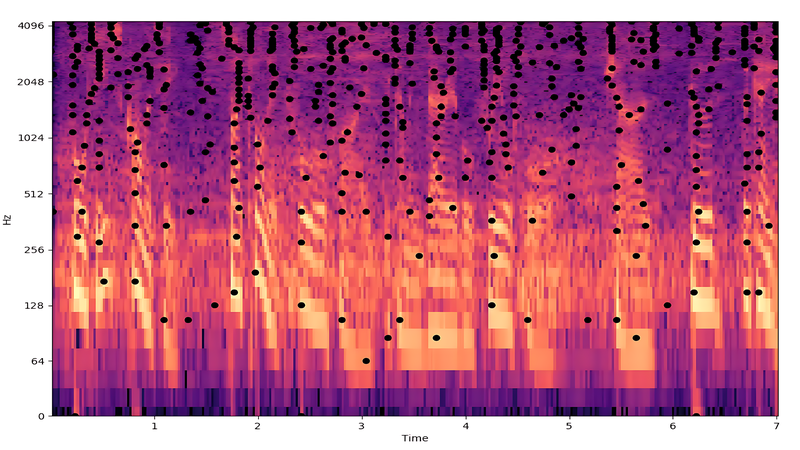
- Constellation Map: These peaks form a sparse “star map” of the audio.
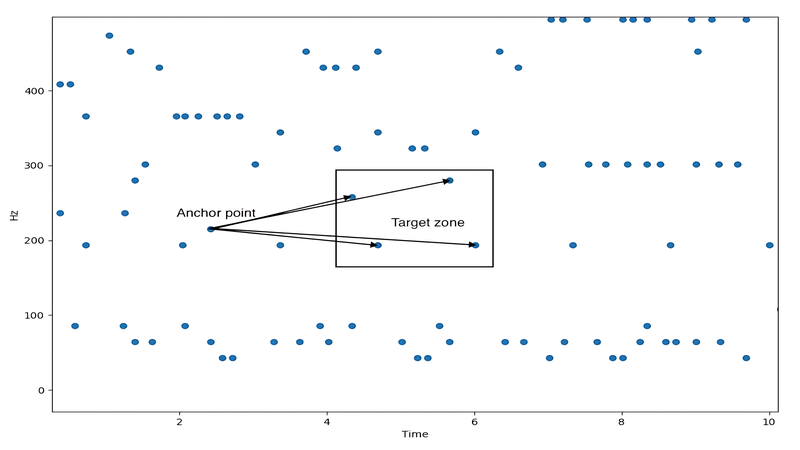
- Combinatorial Hashing: Pairs of peaks (an anchor peak + nearby target peaks) are encoded into 32- or 64-bit hashes. Each hash typically encodes: frequency of anchor, frequency of target, and time delta between them.
- Database Search: Hashes are queried using Locality Sensitive Hashing (LSH) or inverted indexes, allowing approximate nearest-neighbor search across billions of stored fingerprints in milliseconds
This approach is incredibly efficient and has powered systems like Shazam since the early 2000s.
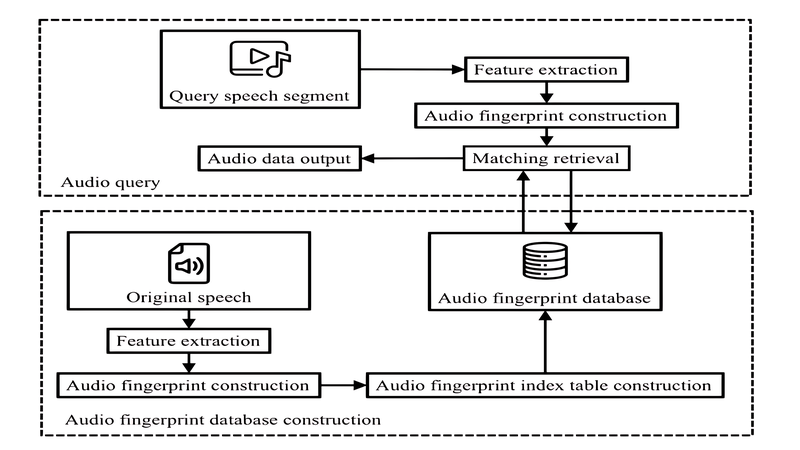
Broadcast Monitoring
Broadcast monitoring is one of the most demanding real-world applications of audio fingerprinting. It must process continuous, high-volume streams with near-perfect accuracy.
How It Works in Practice:
- Continuous Ingestion: Audio from FM, DAB, satellite, or internet streams is captured 24/7, often at 44.1 kHz or higher.
- Overlapping Segmentation: The stream is divided into short, overlapping windows (e.g., 5–10 seconds with 50–80% overlap) to avoid missing transitions between songs or ads.
- Real-Time Fingerprint Extraction: For each window, a spectrogram is computed, peaks are extracted, and thousands of hashes are generated per minute. This runs on dedicated servers or edge devices.
- Massive Reference Database: Millions of reference tracks and commercials are pre-fingerprinted and indexed. The database can contain tens of billions of hashes.
- Matching Engine: Incoming fingerprints are queried against the database. A match requires a sufficient density of hash collisions within a short time window. The system calculates a confidence score based on the number of matches, temporal alignment, and robustness to distortions. It tolerates extreme real-world conditions: background noise, talk-over, 64 kbps compression, reverb, and even partial signal overlap.
- Output & Reporting: Every detection logs a precise timestamp, match duration, content ID, and confidence level. These feed into automated royalty reports, ad verification dashboards, and regulatory compliance tools.
The entire pipeline must handle massive throughput while keeping false positives extremely low, a significant engineering challenge.
Podcasts
The explosion of podcasting has created new challenges: long-form content, heavy speech, spontaneous recordings, and complex monetization.
Audio fingerprinting helps podcast platforms and creators by automatically scanning episodes before publishing to detect copyrighted music in intros, outros, or background, identifying duplicate or reposted content (including AI-generated clones), verifying that host-read sponsorship messages were delivered in full and enabling precise segment-level analytics, which parts of an episode get the most listens or rewinds.
Because podcasts are dominated by speech rather than music, classic peak-based methods are less effective here. This is exactly where neural approaches shine.
Neural Embeddings
Traditional peak-based fingerprinting, while remarkably effective, is increasingly reaching its limits. AI-generated music, deepfakes, heavy remixes, and spoken-word content in podcasts often confuse classic systems that rely on distinct spectral peaks.
This is where neural embeddings represent a fundamental paradigm shift. Instead of converting audio into sparse, hand-crafted hashes, modern foundation models transform short audio segments into dense, high-dimensional vectors, typically between 256 and 1024 dimensions. These vectors don’t just capture surface-level acoustic features; they encode the deeper semantic, stylistic, and emotional essence of the sound.
The process begins by feeding a short audio clip (usually 3 to 10 seconds) into a large pretrained model such as MERT, Mu or wav2vec 2.0. The model then outputs a fixed-size embedding, essentially a compact numerical representation that summarizes the audio’s unique characteristics. These models are trained using contrastive learning: different versions of the same audio (with added noise, pitch shifts, compression, or reverb) are pulled closer together in vector space, while unrelated audio clips are pushed apart. As a result, the embeddings become highly robust to real-world distortions.
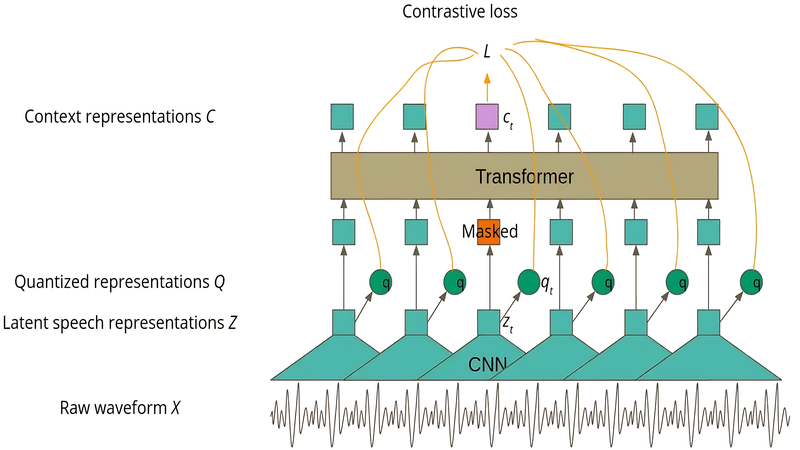
The advantages are significant. Neural embeddings handle extreme distortions and generative content far better than traditional methods. They excel at understanding spoken content and mixed audio, typical in podcasts. Most importantly, they can measure how similar two recordings are, not just whether they match, which is becoming critical for copyright enforcement in the age of AI remixes and deepfakes. They also enable true segment-level analysis rather than whole-track identification.
Today, the most effective solutions are hybrid systems: classic peak-based fingerprinting handles fast, high-volume matching, while neural embeddings step in for the difficult, ambiguous, or high-stakes cases. This combination is rapidly becoming the new industry standard.
Conclusion
Audio fingerprinting has evolved from a clever trick that lets your phone identify songs into a critical piece of infrastructure for the entire audio ecosystem. It quietly powers ad verification, content protection, and audience analytics across radio, television, and podcasts.
With neural embeddings, we’re moving beyond simple recognition toward true audio understanding, detecting not just what was played, but how it relates to other content, whether it’s original, and how audiences engage with it.
As audio content continues to explode in volume and complexity, fingerprinting technologies will only become more essential.




Your Content Deserves the Best Protection
Discover how our innovative AI watermarking tool can transform your digital protection strategy. Request a demo and let us guide you through features tailored to your needs.