Speaker Signatures in ElevenLabs Voices

Trust and Transparency in the Age of Synthetic Voices
AI-generated voices are no longer a curiosity; they’re everywhere: in podcasts, audiobooks, games, and even customer service. This explosion in accessibility brings incredible creative potential, but also raises serious questions about misuse, authenticity, and trust.
We see that the companies leading this space are forward-thinking and responsible. We don’t believe that their goal is to create technology that deceives or replaces people, but rather to empower creativity, make high-quality content more accessible, and build tools that honor authenticity and trust.
At the same time, the rapid progress of voice cloning systems has created an urgent need for reliable deepfake detection. When synthetic speech becomes nearly indistinguishable from real speech to the human ear, traditional listening-based verification is no longer enough. This is especially important in settings where voice carries authority or identity, such as journalism, public communication, entertainment, and fraud prevention.
The challenge is subtle. A cloned voice is not a direct copy of an original recording. It is a reconstruction generated from learned representations of a speaker’s vocal traits. That means the synthetic output may preserve much of the speaker’s identity while still introducing artifacts or distortions that differ from authentic human speech in systematic ways. For researchers, this raises a fundamental question: What traces of synthesis remain when a model recreates a voice?
Our goal is to understand which representations of speech remain stable across real and cloned audio, and which ones reveal the presence of generation. We believe that answering this question is essential for building the next generation of deepfake detection methods, systems that can identify synthetic speech not just by how it sounds, but by how it behaves in a learned representation space.
Turning Voices into Vectors
As part of our journey to understand this challenge, we decided to take a step back and conduct an independent analysis of modern voice cloning systems, with the aim of understanding what stays and what shifts when a real voice becomes a digital twin.
We used ElevenLabs’ powerful Instant Voice Cloning feature as our testbed. Our dataset mixed real and synthetic voices from about 30 speakers pulled from a few well known English language datasets. We deliberately chose a blend of genders, accents, and recording conditions, from clean studio audio to clips with a background noise, so our findings would reflect the messy diversity of real-world sound.
Each speaker contributed a handful of genuine recordings, usually around 20 clips (a bit fewer for the Common Voice set). Those authentic voices became the foundation for cloning. Using ElevenLabs, we generated synthetic versions for every speaker. Each cloned voice then generated the same five sentences under three stability settings: 50%, 75%, and 100%. That gave us 15 clones per speaker, enough to explore how subtle changes in synthesis parameters influence the preservation of identity.
With all those voices ready, it was time for the fun part: turning sound into math. We used the open source ECAPA2 model, one of the best speaker representation models available to extract speaker embeddings. Think of it as a 192-dimensional fingerprint that captures the unique timbre and tone of each voice. The closer two embeddings are, the higher the chance that they belong to the same speaker.
By comparing embeddings of real and cloned voices, we could finally measure how faithfully ElevenLabs preserves speaker identity. Spoiler: the clones were impressively close, but not identical.
What We Found
When we measured cosine similarity (the mathematical “closeness”) between embeddings the results were striking. As shown in Figure 1, ElevenLabs’ cloned voices scored consistently high, even when trained on just a few seconds of audio. In other words, from the model’s perspective, the clones sounded very much like the originals.
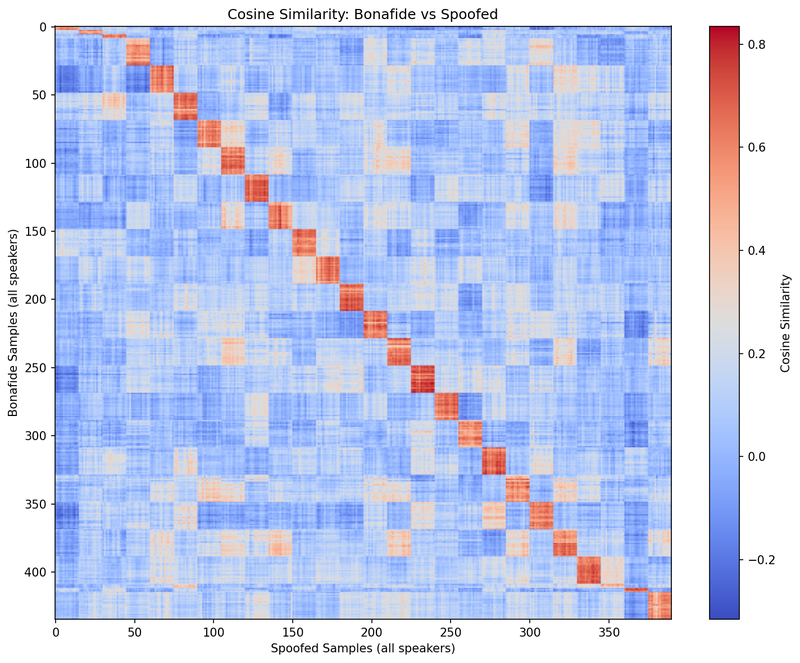
Figure 1: Cosine similarity between real and cloned samples across all speakers.
But that’s not the whole story. Machines are great at capturing tone and timbre, yet human voices carry more than just frequency curves. Micro-pauses, breath timing, and tiny variations in pitch contour all contribute to what makes a person’s voice unmistakably theirs. So we looked for subtle shifts in the embedding space that might reveal these nuances.
To visualize this, we projected our high-dimensional embeddings into two dimensions using Principal Component Analysis (PCA). Think of it as flattening a 192D cloud into something we can actually see.
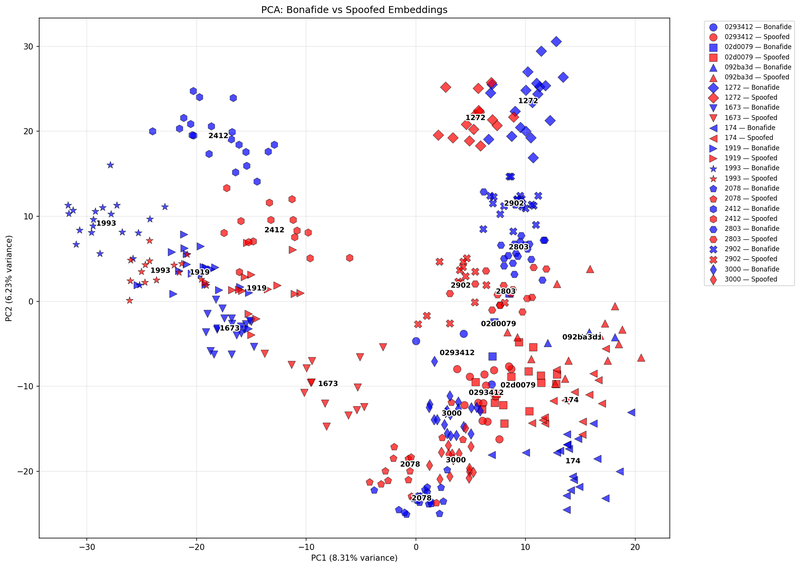
Figure 2: Speaker group 1 (PC1 vs. PC2).
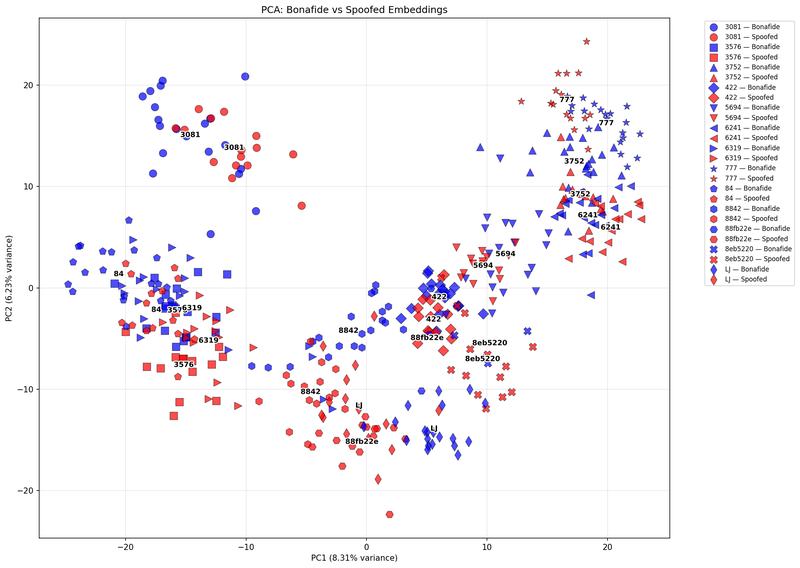
Figure 3: Speaker group 2 (PC1 vs. PC2).
Figures 2 and 3 show PCA visualizations of real (blue) and cloned (red) samples. Each speaker is represented by a unique marker, and the accompanying text labels indicate the centroid of that speaker’s bonafide and cloned sample clusters.
The PCA plots told an interesting story: cloned and genuine samples often shared overlapping clusters, but the clones consistently drifted just enough to reveal they weren’t identical twins. They were more like very convincing siblings: similar DNA, different heartbeat.
Still, PCA has its limits. By squeezing our 192-dimensional voice universe into just two dimensions, we lose a lot of nuance-kind of like trying to capture a full orchestra through a single microphone. In this simplified view, many speakers blend together, and the plot doesn’t clearly separate who’s who. In fact, the first two principal components explained less than 15% of the total variance, which means most of the real structure is hiding beyond what we can see here. So while PCA gave us a glimpse of how close (and yet different) the clones really are, it’s only scratching the surface of a much deeper story.
To dig deeper, we switched to a more nonlinear lens: t-Distributed Stochastic Neighbor Embedding (t-SNE). This visualization method preserves local structure better, revealing patterns hidden in high-dimensional data.
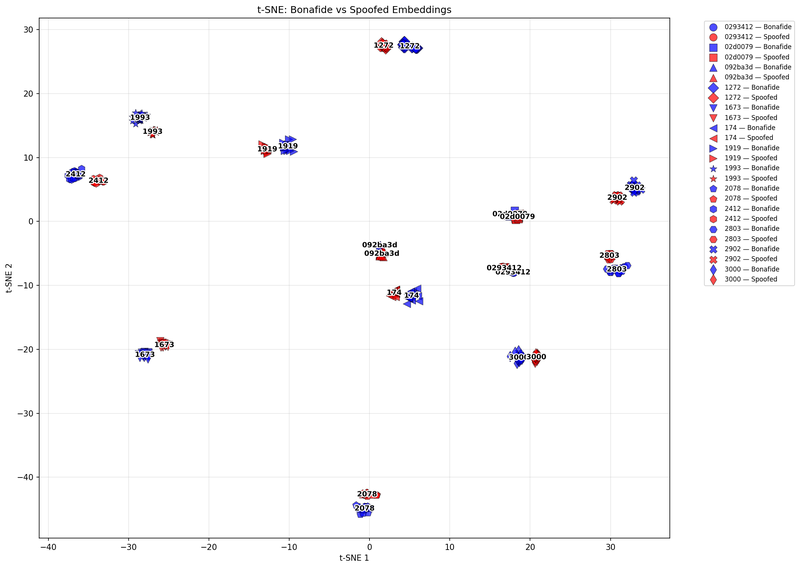
Figure 4: t-SNE analysis - speaker group 1.
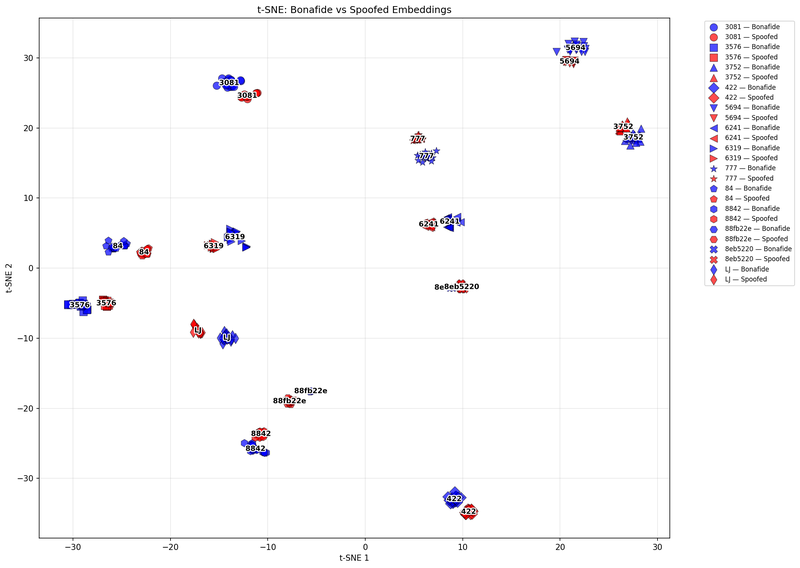
Figure 5: t-SNE analysis - speaker group 2.
And there it was: cloned and real samples occupied neighboring but distinct regions in the t-SNE plots. The overlap confirmed that the voice identity was faithfully reproduced, but the separation hinted at something more profound. Cloning captures the surface of the voice, not its soul. Somewhere in the waveform, there’s still a trace of the generator.
Takeaway
Our exploration of ElevenLabs’ voices points to a conclusion that is both impressive and unsettling: modern voice cloning systems are becoming realistic enough that the distinction between real and synthetic speech is rapidly losing perceptual meaning.
In the ECAPA2 embedding space, cloned voices remain very close to their real counterparts, confirming that today’s systems can preserve speaker identity with remarkable fidelity. But they are not perfectly aligned. The small but consistent gap suggests that synthetic speech may still carry detectable structural traces of generation, even when it sounds authentic to human listeners.
That is encouraging for research, but it is also a warning. The future will not be secured by hoping people can keep hearing the difference. They won’t. Deepfakes are likely to keep improving until, in many practical situations, they are good enough to win. When that happens, trust in audio will have to depend on other layers: representation-based detection, provenance, authentication, watermarking, and systems designed for proof rather than intuition.
That is why this line of research matters. The real challenge is no longer simply making synthetic voices sound real. That challenge is already being solved. The harder and more important challenge now is learning how to preserve trust when they do.




Your Content Deserves the Best Protection
Discover how our innovative AI watermarking tool can transform your digital protection strategy. Request a demo and let us guide you through features tailored to your needs.